
 Zaman Yönetimi: Zamanı Yönetmek Değil, Hayatı Yöne...
Zaman Yönetimi: Zamanı Yönetmek Değil, Hayatı Yöne...
 Veri Bilimi Eğitimi
Veri Bilimi Eğitimi
 Etkili CV Hazırlama
Etkili CV Hazırlama




Büyük Dil Modelleri (LLM) ile çalışan sistemlerin güvenilirliğini tartışırken, genellikle modelin parametre sayısı veya eğitim verisi üzerinde durulur. Ancak çoğu zaman gözden kaçan çok temel bir teknik detay vardır: Verileri modele hangi formatta sunuyoruz? LLM veri formatı karşılaştırması, bir yapay zeka sisteminin sadece ne kadar "akıllı" cevap vereceğini değil, aynı zamanda operasyonel maliyetlerini de doğrudan belirleyen kritik bir unsurdur.
Özellikle RAG pipeline optimizasyonu süreçlerinde, tabloların veya hiyerarşik verilerin (JSON, CSV, Markdown vb.) modele aktarılma biçimi, sistemin genel başarısını etkiler. Yanlış format seçimi, modelin veriyi yanlış yorumlamasına neden olarak yapay zeka veri doğruluk oranlarını düşürebilir veya gereksiz yüksek LLM token maliyeti ile bütçenizi zorlayabilir. Bu derin incelemede, farklı veri formatlarının performansını teknik veriler ve benchmark sonuçlarıyla analiz ediyoruz.
LLM'ler Tabloları Anlamada Hangi Formatı Tercih Ediyor?
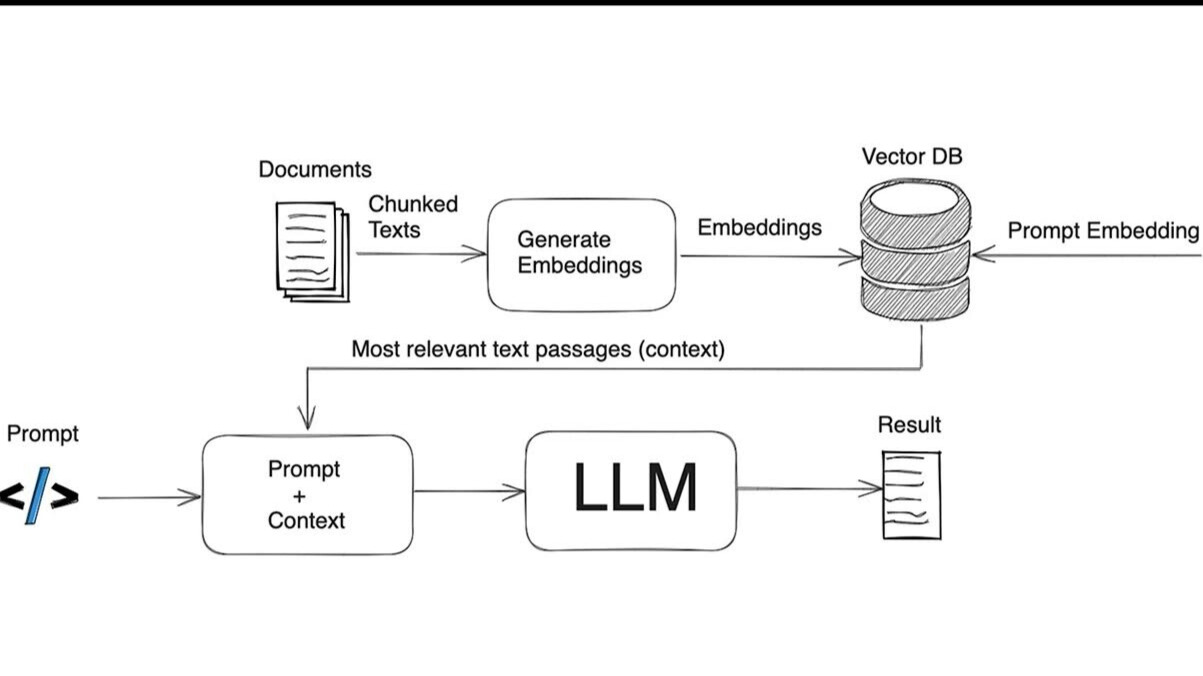
Yapay zeka modellerine 1.000 kayıtlık veri setleri üzerinden 1.000 farklı soru sorularak yapılan kontrollü deneyler, format seçiminin sistem doğruluğu üzerindeki etkisini çarpıcı bir şekilde ortaya koymaktadır.
- Markdown-KV (Anahtar-Değer) Formatı: Yapılan testlerde %60.7 doğruluk oranıyla zirveye yerleşmiştir. Klasik tablolardan ziyade her kaydı anahtar: değer çiftleri şeklinde sunan bu yapı, modelin veriler arasındaki ilişkiyi kurmasını kolaylaştırır.
- XML ve INI: %56 civarındaki doğruluk oranlarıyla Markdown-KV'yi takip eder. Ancak XML'in token maliyeti oldukça yüksektir.
- CSV ve JSONL Performansı: Şaşırtıcı bir şekilde, veri biliminde en çok kullanılan CSV JSONL performansı oldukça düşük kalmıştır. CSV %44.3, JSONL ise %45 doğruluk oranında kalmaktadır. Bu durum, LLM'lerin virgülle ayrılmış ham verileri anlamlandırmakta zorlandığını gösterir.
- Token Verimliliği: CSV, en az token tüketen format (19,524 token) olmasına rağmen en düşük doğruluk oranlarından birine sahiptir. Markdown-KV ise CSV'den 2.7 kat daha fazla token tüketmesine rağmen 16 puanlık bir doğruluk avantajı sağlar.
Hiyerarşik (İç İçe) Verilerde En İyi Format Hangisi?
Modern AI sistemleri genellikle API yanıtları veya konfigürasyon dosyaları gibi iç içe geçmiş (nested) verileri işlemek zorundadır. LLM veri formatı karşılaştırması bu alanda da modelden modele farklılık gösteren sonuçlar sunmaktadır.
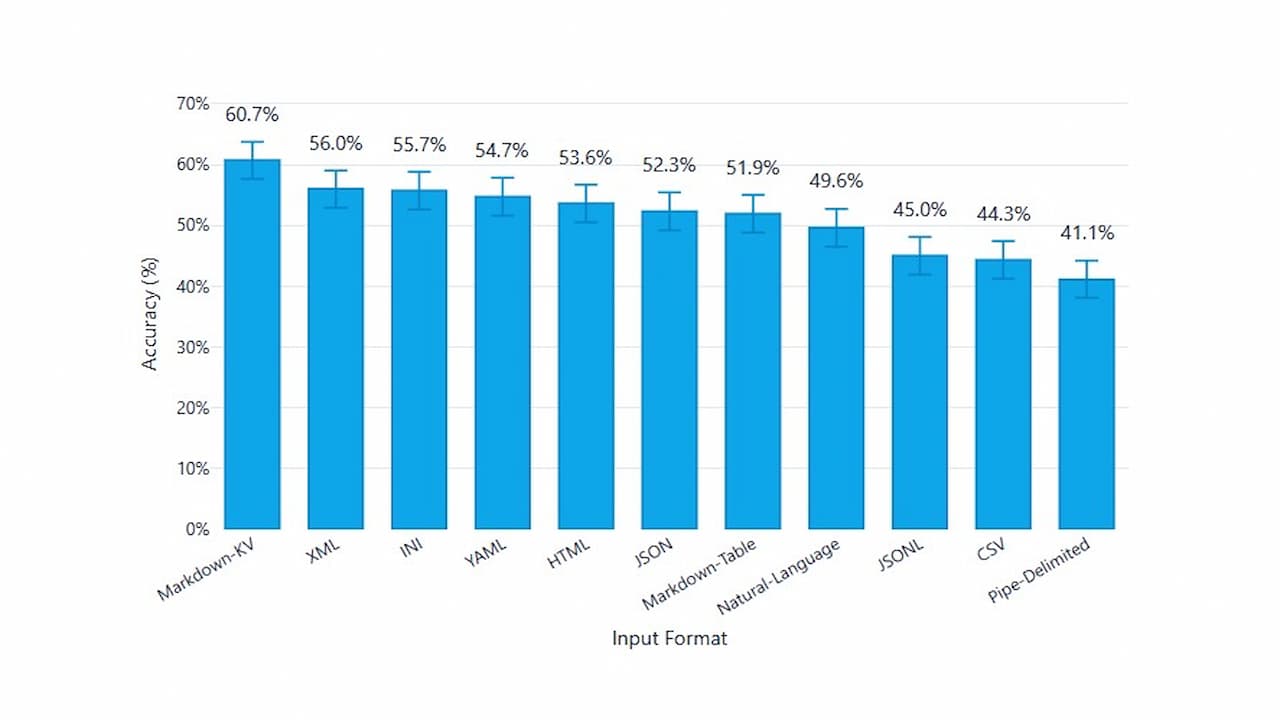
- YAML- Doğruluk Lideri: GPT-5 Nano ve Gemini 2.5 Flash Lite modellerinde YAML en yüksek performansı göstermiştir. Girintiye dayalı görsel hiyerarşi, modelin karmaşık yapıları daha iyi "görmesini" sağlar.
- Markdown- Maliyet Şampiyonu: Markdown, tüm modellerde en token-verimli format olmuştur. JSON'dan %34-38, YAML'dan ise yaklaşık %10 daha az token tüketir. Gerekli doğruluğu korurken maliyeti minimize etmek isteyenler için idealdir.
- JSON'un Zayıflığı: Yaygın kullanımına rağmen JSON, GPT-5 ve Gemini modellerinde beklenenden daha kötü performans göstermiştir. Sadece Llama 3.2 3B Instruct modelinde format hassasiyeti düşük olduğu için JSON kabul edilebilir sonuçlar vermiştir.
- XML'den Kaçının: XML, hem en yüksek token tüketimine sahiptir hem de doğruluk oranlarında genellikle son sıralarda yer alır. Tekrarlayan etiket yapıları (<tag></tag>), modelin dikkat mekanizmasını (attention) dağıtabilir.
Format Seçimi RAG Pipeline Doğruluğunu Nasıl Etkiler?
- Ne Etkilenir? Bir RAG (Retrieval-Augmented Generation) sisteminin doğruluğu, alınan bilginin modele nasıl beslendiğine bağlıdır. Yanlış format, modelin veriyi "halüsinasyon" görerek yanlış raporlamasına yol açar.
- Neden Önemli? Yapay zeka veri doğruluk oranındaki %10'luk bir düşüş, müşteri hizmetleri botu veya finansal analiz aracı için felaket anlamına gelebilir.
- Nasıl Optimize Edilir? Eğer doğruluk her şeyden önemliyse Markdown-KV veya YAML kullanılmalıdır. Eğer bütçe kısıtlıysa ve veri yoğunsa Markdown tabloları iyi bir orta yoldur.
- Nerede Kullanılır? Veri tabanı sorgu sonuçlarının LLM'e aktarıldığı her noktada bu optimizasyon hayati önem taşır.
- Kim Yapmalı? Veri mühendisleri ve AI mimarları, prompt mühendisliği aşamasında verinin formatını dönüştürmeyi bir standart haline getirmelidir.
Token Maliyeti ve Performans Dengesi
Veri formatlarının token tüketimi, doğrudan işletme maliyetidir. Örneğin, XML formatı Markdown'a göre %80 daha fazla token gerektirir. Bu, aynı veriyi işlemek için neredeyse iki katı para ödemek demektir.
Performans-Maliyet Matrisi:
- Doğruluk Öncelikli (Yüksek Bütçe): Markdown-KV (Tablolar için), YAML (Nested veriler için).
- Denge Öncelikli: Markdown Tables.
- Düşük Maliyet Öncelikli (Düşük Doğruluk Kabulü): CSV veya JSONL.
Uygulama İçin Stratejik Öneriler
LLM veri formatı karşılaştırması sonuçlarına göre, varsayılan olarak CSV veya JSON kullanmak sisteminizin potansiyelini kısıtlıyor olabilir. Teknik derinliği koruyarak şu adımları izlemeniz önerilir:
- Sisteminizde yoğun olarak tablo verisi kullanılıyorsa, veriyi modele göndermeden önce Markdown-KV formatına dönüştüren bir ara katman ekleyin.
- Karmaşık yapılandırma dosyaları veya kataloglar için YAML formatını standart hale getirin.
- Modelinizin (GPT, Llama, Gemini vb.) hangi formata daha duyarlı olduğunu belirlemek için kendi veri setinizle ufak ölçekli benchmark testleri yapın.
- Gereksiz token israfını önlemek için XML kullanımını minimuma indirin.
En "doğru" format yoktur; ancak hedeflerinize göre en "optimize" format vardır. Doğruluk kritikse YAML ve Markdown-KV, maliyet kritikse Markdown tabloları 2025 ve sonrası için yapay zeka dünyasının en güçlü standartlarıdır. Sistemin başarısı, verinin sadece varlığına değil, modelin onu en saf ve anlaşılır haliyle tüketmesine bağlıdır.
